











 Michael Cain
Michael Cain 0
0  4770
4770 1084
1084
Skrobaki do sieci automatycznie zbierają informacje i dane, które zwykle są dostępne tylko poprzez odwiedzenie strony internetowej w przeglądarce. Robiąc to autonomicznie, skrypty do przeglądania stron internetowych otwierają świat możliwości w eksploracji danych, analizie danych, analizie statystycznej i wielu innych.
Dlaczego skrobanie stron internetowych jest przydatne
Żyjemy w czasach, w których informacje są łatwiej dostępne niż kiedykolwiek wcześniej. Infrastruktura wykorzystywana do dostarczania tych właśnie słów, które czytasz, jest sposobem na uzyskanie większej wiedzy, opinii i wiadomości niż kiedykolwiek była dostępna dla ludzi w historii ludzi.
Tak bardzo, że mózg najmądrzejszej osoby, zwiększony do 100% wydajności (ktoś powinien nakręcić o tym film), nadal nie byłby w stanie pomieścić 1/1000 danych przechowywanych w Internecie w samych Stanach Zjednoczonych.
Cisco oszacował w 2016 r., Że ruch w Internecie przekroczył jeden zettabajt, czyli 1 000 000 000 000 000 000 000 000 bajtów lub jeden bajt sekstylionu (śmiej się, chichocz w sekstylionie). Jeden zettabyte to około cztery tysiące lat streamingu Netflix. Byłoby to równoważne, gdybyś, nieustraszony czytelniku, przesyłał strumieniowo pakiet Office od początku do końca bez zatrzymywania 500 000 razy.
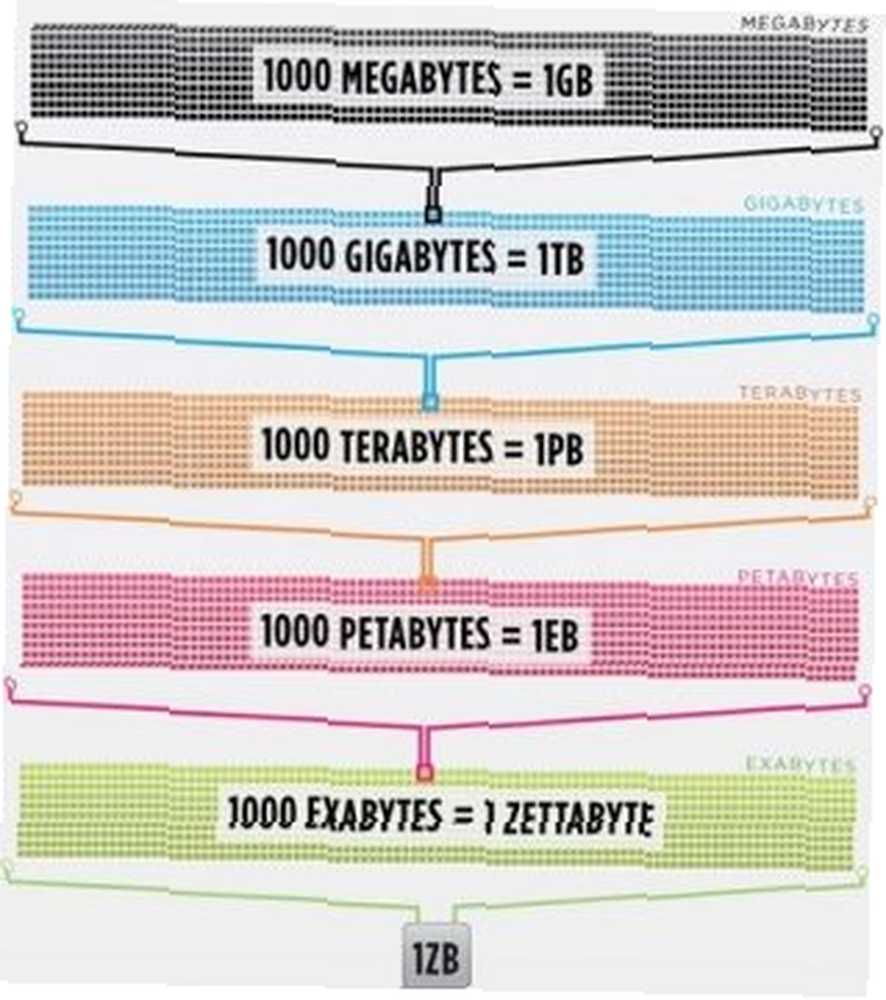 Źródło zdjęcia: Cisco / The Dawn of the Zettabyte
Źródło zdjęcia: Cisco / The Dawn of the Zettabyte
Wszystkie te dane i informacje są bardzo zastraszające. Nie wszystko jest w porządku. Niewiele z nich dotyczy codziennego życia, ale coraz więcej urządzeń dostarcza te informacje z serwerów na całym świecie prosto do naszych oczu i do naszych mózgów.
Ponieważ nasze oczy i mózg tak naprawdę nie są w stanie poradzić sobie z wszystkimi tymi informacjami, skrobanie Internetu stało się przydatną metodą gromadzenia danych programowo z Internetu. Pozyskiwanie danych z Internetu to abstrakcyjny termin określający czynność wydobywania danych ze stron internetowych w celu ich lokalnego zapisania.
Pomyśl o typie danych i prawdopodobnie możesz je zebrać, skrobiąc sieć. Listy nieruchomości, dane sportowe, adresy e-mail firm w Twojej okolicy, a nawet teksty piosenek Twojego ulubionego artysty można wyszukać i zapisać, pisząc mały skrypt.
W jaki sposób przeglądarka pobiera dane sieciowe?
Aby zrozumieć skrobaczki do sieci, musimy najpierw zrozumieć, jak działa sieć. Aby przejść do tej witryny, musisz wpisać “makeuseof.com” do przeglądarki lub kliknąłeś link z innej strony internetowej (powiedz nam, gdzie naprawdę chcemy wiedzieć). Tak czy inaczej, kolejne kilka kroków są takie same.
Po pierwsze, Twoja przeglądarka pobierze podany lub kliknięty adres URL (wskazówka: najedź kursorem na link, aby zobaczyć adres URL na dole przeglądarki, zanim klikniesz, aby uniknąć punkowstwa) i utworzy “żądanie” wysłać na serwer. Serwer przetworzy następnie żądanie i odeśle odpowiedź.
Odpowiedź serwera zawiera HTML, JavaScript, CSS, JSON i inne dane potrzebne do umożliwienia przeglądarce utworzenia strony internetowej dla przyjemności oglądania.
Sprawdzanie elementów sieci
Nowoczesne przeglądarki pozwalają nam na pewne szczegóły dotyczące tego procesu. W przeglądarce Google Chrome w systemie Windows możesz nacisnąć Ctrl + Shift + I lub kliknij prawym przyciskiem myszy i wybierz Sprawdzać. Okno wyświetli ekran wyglądający następująco.
Lista opcji z zakładkami u góry okna. Interesujące jest teraz Sieć patka. To da szczegółowe informacje o ruchu HTTP, jak pokazano poniżej.
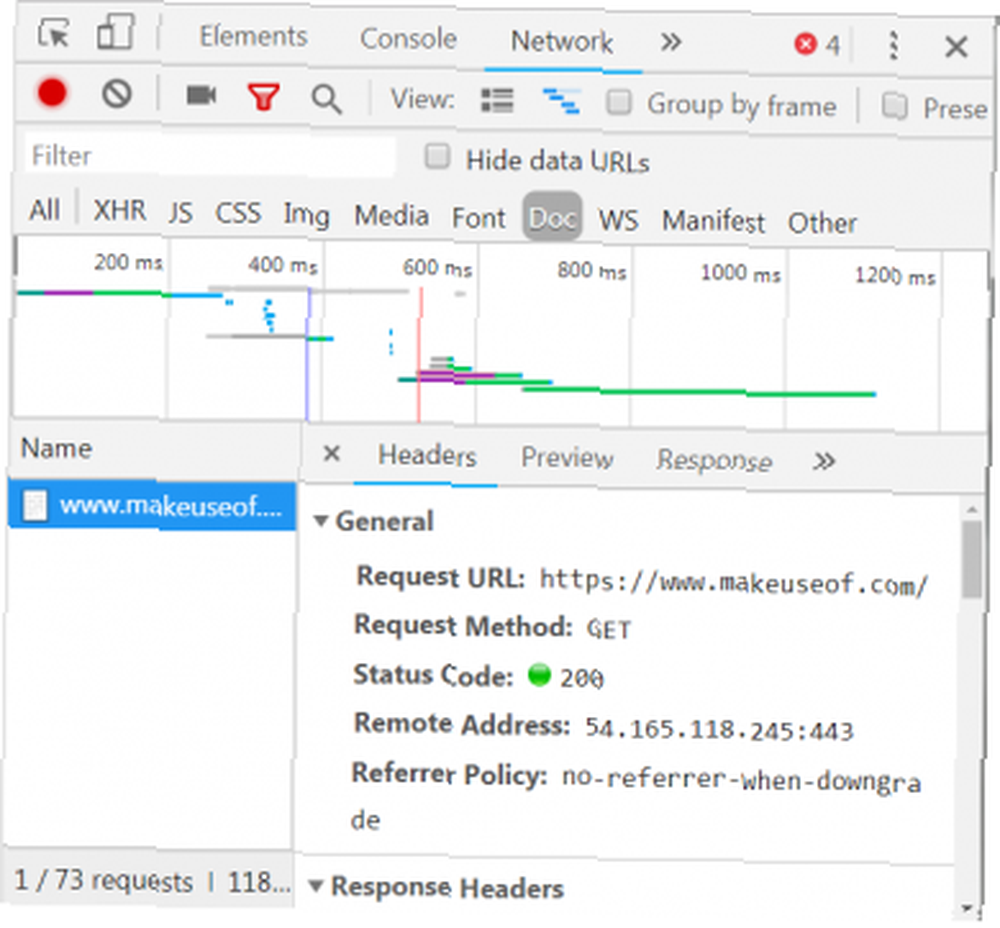
W prawym dolnym rogu widzimy informacje o żądaniu HTTP. Adres URL jest tym, czego oczekujemy, i “metoda” jest HTTP “OTRZYMAĆ” żądanie. Kod stanu z odpowiedzi jest wymieniony na 200, co oznacza, że serwer uznał żądanie za prawidłowe.
Pod kodem statusu znajduje się adres zdalny, który jest publicznym adresem IP serwera makeuseof.com. Klient otrzymuje ten adres za pomocą protokołu DNS. Dlaczego zmiana ustawień DNS zwiększa prędkość Internetu Dlaczego zmiana ustawień DNS zwiększa prędkość Internetu Zmiana ustawień DNS jest jednym z tych drobnych usprawnień, które mogą mieć duży zwrot z codziennych prędkości Internetu. .
Następna sekcja zawiera szczegółowe informacje na temat odpowiedzi. Nagłówek odpowiedzi zawiera nie tylko kod stanu, ale także typ danych lub treści, które zawiera odpowiedź. W tym przypadku patrzymy “text / html” ze standardowym kodowaniem. To mówi nam, że odpowiedzią jest dosłownie kod HTML do renderowania strony.
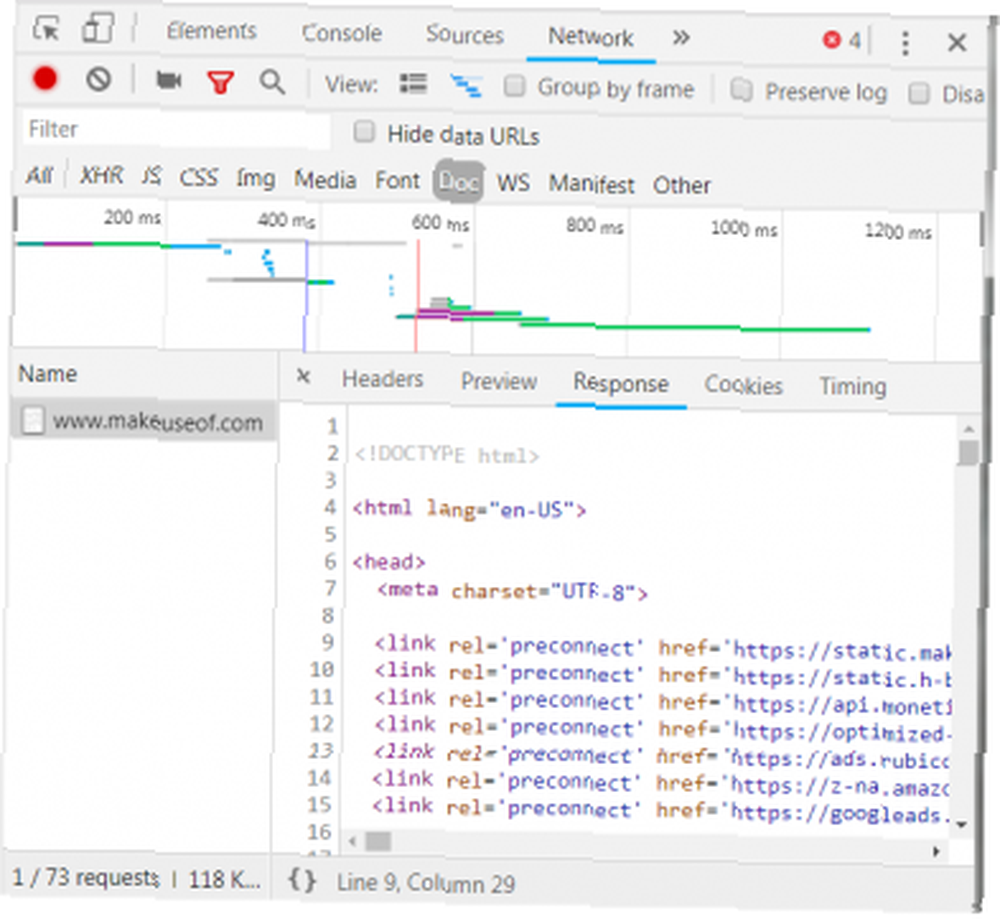
Inne rodzaje odpowiedzi
Ponadto serwery mogą zwracać obiekty danych w odpowiedzi na żądanie GET, a nie tylko HTML do renderowania strony internetowej. Interfejs programowania aplikacji (lub API) strony internetowej Czym są interfejsy API i jak otwarte interfejsy API zmieniają Internet Czym są interfejsy API i jak otwarte interfejsy API zmieniają Internet Czy zastanawiałeś się kiedyś, jak programy na twoim komputerze i odwiedzane strony internetowe „mówią” do siebie? zazwyczaj wykorzystuje ten rodzaj wymiany.
Przeglądając kartę Sieć, jak pokazano powyżej, możesz sprawdzić, czy istnieje tego rodzaju wymiana. Podczas badania otwartej tabeli liderów CrossFit wyświetlane jest żądanie wypełnienia tabeli danymi.
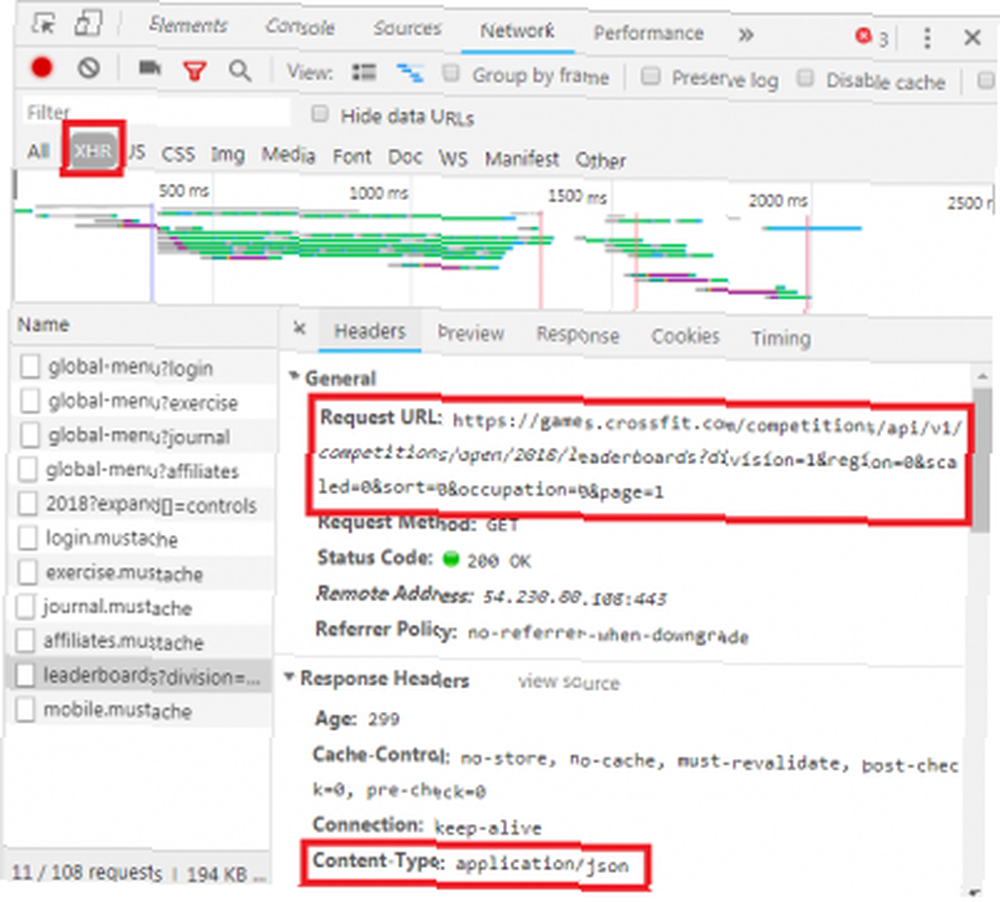
Kliknięcie odpowiedzi powoduje wyświetlenie danych JSON zamiast kodu HTML w celu renderowania strony internetowej. Dane w JSON to seria etykiet i wartości na warstwowej, zarysowanej liście.
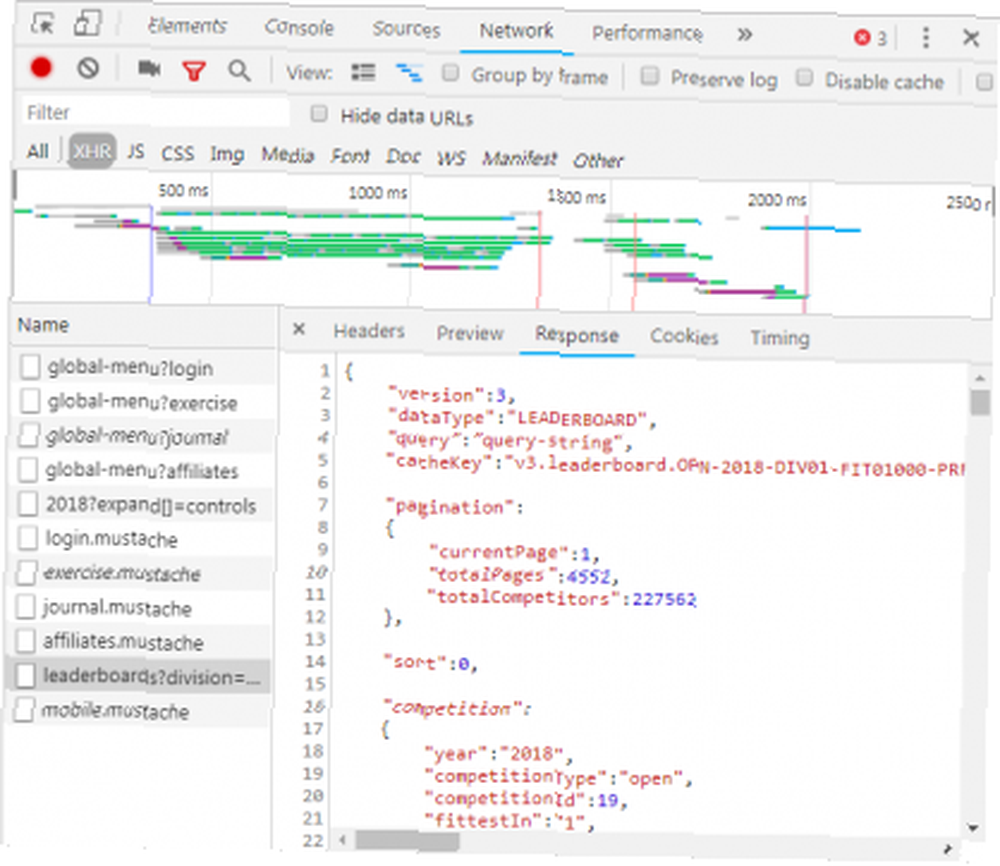
Ręczne analizowanie kodu HTML lub przechodzenie przez tysiące par klucz / wartość JSON przypomina czytanie Matrycy. Na pierwszy rzut oka wygląda jak bełkot. Może być za dużo informacji, aby ręcznie je zdekodować.
Skrobaki internetowe na ratunek!
Teraz zanim zaczniesz prosić o niebieską pigułkę, aby się stąd wydostać, powinieneś wiedzieć, że nie musimy ręcznie dekodować kodu HTML! Niewiedza nie jest błogością, a ten stek jest pyszne.
Skrobaczka internetowa może wykonać te trudne zadania. Frameworki są dostępne w języku Python, JavaScript, Node i innych językach. Jednym z najprostszych sposobów na rozpoczęcie skrobania jest użycie Pythona i Pięknej Zupy.
Skrobanie witryny za pomocą Pythona
Rozpoczęcie pracy zajmuje tylko kilka linii kodu, o ile masz zainstalowany Python i BeautifulSoup. Oto mały skrypt, aby uzyskać źródło strony internetowej i pozwolić, aby BeautifulSoup je oceniła.
z importu bs4 Żądania importu BeautifulSoup url = "http://www.athleticvolume.com/programming/" content = requests.get (url) soup = BeautifulSoup (content.text) print (zupa) Po prostu wysyłamy żądanie GET do adresu URL, a następnie umieszczamy odpowiedź w obiekcie. Drukowanie obiektu wyświetla kod źródłowy HTML adresu URL. Proces wygląda tak, jakbyśmy ręcznie przeszli na stronę i kliknęli Pokaż źródło.
W szczególności jest to strona internetowa, która publikuje treningi w stylu CrossFit każdego dnia, ale tylko jeden dziennie. Możemy zbudować nasz skrobak, aby codziennie ćwiczyć, a następnie dodać go do agregującej listy treningów. Zasadniczo możemy stworzyć tekstową historyczną bazę danych treningów, którą możemy łatwo przeszukiwać.
Magią BeaufiulSoup jest możliwość przeszukiwania całego kodu HTML za pomocą wbudowanej funkcji findAll (). W tym konkretnym przypadku strona korzysta z kilku “sqs-block-content” tagi. Dlatego skrypt musi przeglądać wszystkie te tagi i znajdować ten, który jest dla nas interesujący.
Ponadto istnieje wiele
tagi w sekcji. Skrypt może dodać cały tekst z każdego z tych tagów do zmiennej lokalnej. Aby to zrobić, dodaj prostą pętlę do skryptu:
dla div_class w soup.findAll ('div', 'class': 'sqs-block-content'): recordThis = False dla pw div_class.findAll ('p'): jeśli 'PROGRAM' w p.text. upper (): recordThis = Prawda, jeśli recordThis: program + = p.text program + = '\ n' Voilà! Powstaje skrobak sieciowy.
Skalowanie w górę Skrobanie
Istnieją dwie ścieżki do przodu.
Jednym ze sposobów eksploracji skrobania stron internetowych jest użycie narzędzi, które zostały już zbudowane. Web Scraper (świetna nazwa!) Ma 200 000 użytkowników i jest prosty w obsłudze. Ponadto Parse Hub pozwala użytkownikom eksportować zeskrobane dane do Excela i Arkuszy Google.
Dodatkowo, Web Scraper zapewnia wtyczkę do Chrome, która pomaga wizualizować sposób budowy strony internetowej. Co najważniejsze, według nazwy, jest OctoParse, potężny skrobak z intuicyjnym interfejsem.
Wreszcie, teraz, gdy znasz już tło drapania stron internetowych, podnosząc swój własny mały skrobak internetowy, aby móc się czołgać i uruchamiać Jak zbudować podstawowy przeszukiwacz sieciowy, aby pobrać informacje ze strony internetowej Jak zbudować podstawowy przeszukiwacz sieciowy, aby pobrać informacje z Strona internetowa Czy kiedykolwiek chciałeś przechwytywać informacje ze strony internetowej? Możesz napisać robota, aby poruszać się po witrynie i wyodrębnić tylko to, czego potrzebujesz. sama w sobie jest zabawnym przedsięwzięciem.